


Voici un récap’ des présentations faites par Clément Denis (CTO AODocs) et Jean-Marc Leoni (CTO Akur8) lors de notre dernier Mobitalks Java !
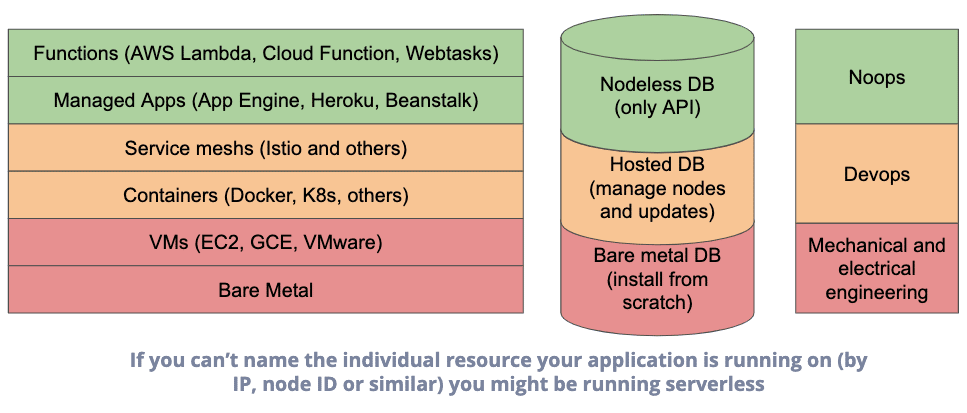
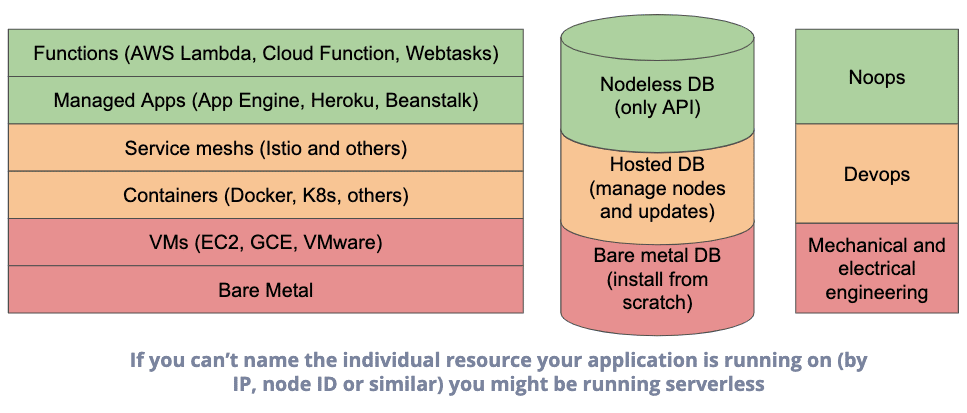
Clément Denis : Java sans serveur avec Google Cloud Platform. Qu’est-ce que Serverless signifie vraiment ?
Clément ne mâche pas ses mots : gérer des serveurs, physiques, virtuels ou en containers, c’est un casse-tête. Si quelqu’un d’autre peut prendre cette corvée, pourquoi hésiter ?
A lire en complément : Qu'est-ce que le développement informatique sur Cloud Native ?
Jusqu’où peut-on pousser l’abstraction côté infrastructure ?
A lire en complément : Comment utiliser les astuces Gmail pour améliorer votre productivité ?
Le serverless ne se limite pas à la production
Développer directement dans le Cloud, ça change tout
Quand vos instances démarrent en un claquement de doigts, travailler sur votre machine locale n’a plus grand intérêt la plupart du temps. Le Cloud devient le terrain de jeu par défaut.
Adopter le “sans serveur” pour l’ensemble de la chaîne, outils compris
L’ensemble des outils courants existe aujourd’hui en version Cloud. Quelques exemples :
- Code : Github, Gitlab, Bitbucket
- Intégration continue : Travis, Gitlab CI, pipelines S3
- Gestion de tickets : Jira Cloud, Gitlab
- IDE : Gitpod
Gardez toujours un œil sur la localisation des données clients
Contrôler les données n’est jamais négociable. Le RGPD ne se résume pas à de la paperasse : chaque sous-traitant impose une vérification attentive. Idéalement, centralisez vos données pour éviter les mauvaises surprises.

Serverless : gains et limites
Moins d’opérations, plus vite, moins cher
Lancer une startup sans équipe DevOps : le “serverless” accélère le produit, pas besoin de renforcer les effectifs tout de suite.
Scalabilité sans plafond
Adopter le modèle serverless impose de tout rendre adaptable à la demande, à l’horizontale. Cela change la façon de concevoir les applications, mais c’est souvent payant.
Mises à jour et sécurité : les géants du cloud veillent
Une faille critique ? Google, Amazon ou Microsoft s’en occupent plus vite que vous ne pourriez le faire en interne, et ça enlève bien du stress.
Le vrai métier, c’est l’application, pas l’infrastructure
Allégé du poids des serveurs, l’énergie est de nouveau consacrée à ce qui compte : la valeur ajoutée pour l’utilisateur.
Performances au rendez-vous… mais gardez un œil sur la facture
La souplesse est bien là, mais la montée en charge peut entraîner quelques surprises sur la ligne budgétaire.
La conception se complexifie
Impossible de faire l’impasse : il faut anticiper la scalabilité dès les premiers schémas, dire adieu aux traitements séquentiels lourds sur un unique thread.
Moins de contrôle sur l’environnement
On ne pilote plus tous les paramètres : parfois, il faut patienter avant de bénéficier d’une nouvelle version de Java.
Dépendance accrue au fournisseur
Migrer une application d’un cloud à l’autre ? L’opération devient vite un vrai parcours du combattant.
Comment fonctionne AODocs ?
Un système de gestion documentaire taillé pour Google Drive
5 millions d’utilisateurs
L’intégration avec G Suite est totale, appuyée par une extension Chrome pour Google Drive et une installation directe sur le domaine. Rien n’échappe à cet écosystème.
Des centaines de millions de fichiers gérés sur Google Drive
L’accélération est impressionnante : la barre du milliard de documents ne tardera pas à tomber.
Une architecture Cloud pensée pour le SaaS
Une application SaaS multi-tenant pour des milliers de clients
Dès le départ, tout a été conçu pour le Cloud : pas de bricolages, pas de réinterprétations. Du vrai SaaS natif.
Des dizaines de millions de requêtes entrantes et sortantes chaque jour
Le système s’ajuste en temps réel, passant de quelques instances à plusieurs centaines suivant le besoin.
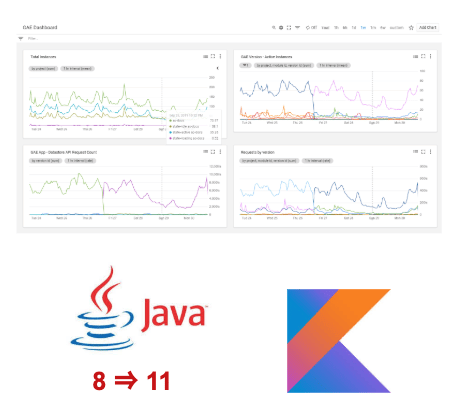
Principalement Java 8, mais l’exploration continue
L’application mise sur Java 8, mais certains microservices évoluent vers Java 11 ou Kotlin.
Des choix techniques clairs et assumés
L’architecture repose notamment sur :
- Servlet 3.1 et App Engine SDK
- Objectifier pour l’ORM (conçu pour Datastore, basé sur les annotations)
- REST diffusé via Cloud Endpoints
- API Google (google-api-services-* et google-cloud-*)
- Guava, Lombok, Jackson, et autres librairies
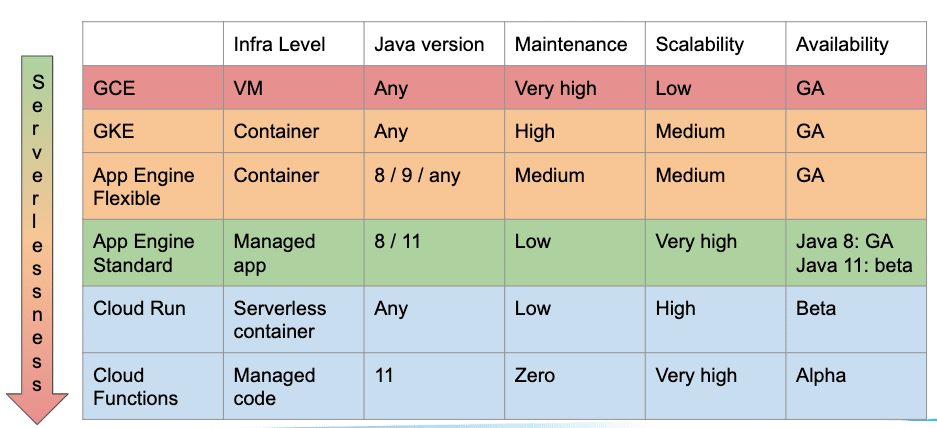
Java sur GCP : panorama des possibilités
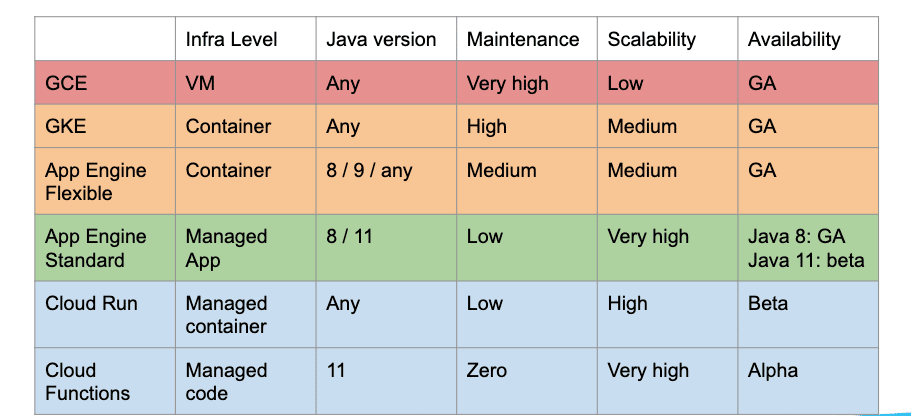
App Engine : le guichet unique du serverless
Des services et des versions multiples
Déployer plusieurs versions d’un même service ? Chaque version dispose de sa propre URL, le routage du trafic s’ajuste à la demande et les bascules s’effectuent sans rupture.
Infrastructure de service flexible
Customisation des domaines, HTTPS natif, gestion du trafic pour les phases de tests ou les déploiements progressifs : il y a de la marge pour ajuster.
Une base de données NoSQL réellement scalable
Datastore et son ORM Java maison, Objectifier, font le travail.
Memcache
Accès ultra-rapide, parfait pour booster Datastore avec un cache de second niveau.
Recherche texte intégral
Sans maintenance, sans prise de tête : le moteur de recherche gère les volumes, peu importe l’échelle.
Tâches planifiées et crons
Découper les traitements ou planifier des actions de routine, tout est nativement prévu.
App Engine pour Java : deux générations, deux philosophies

Comparer les runtimes Java sur App Engine : première vs deuxième génération

Encore un aperçu de ces différences

Java sur GCP : retour sur les options
Surveiller les applications Java : comment s’y prendre ?
Stackdriver et BigQuery : une alliance efficace

Graphiques et alertes Stackdriver : le trio ELK peut rester de côté
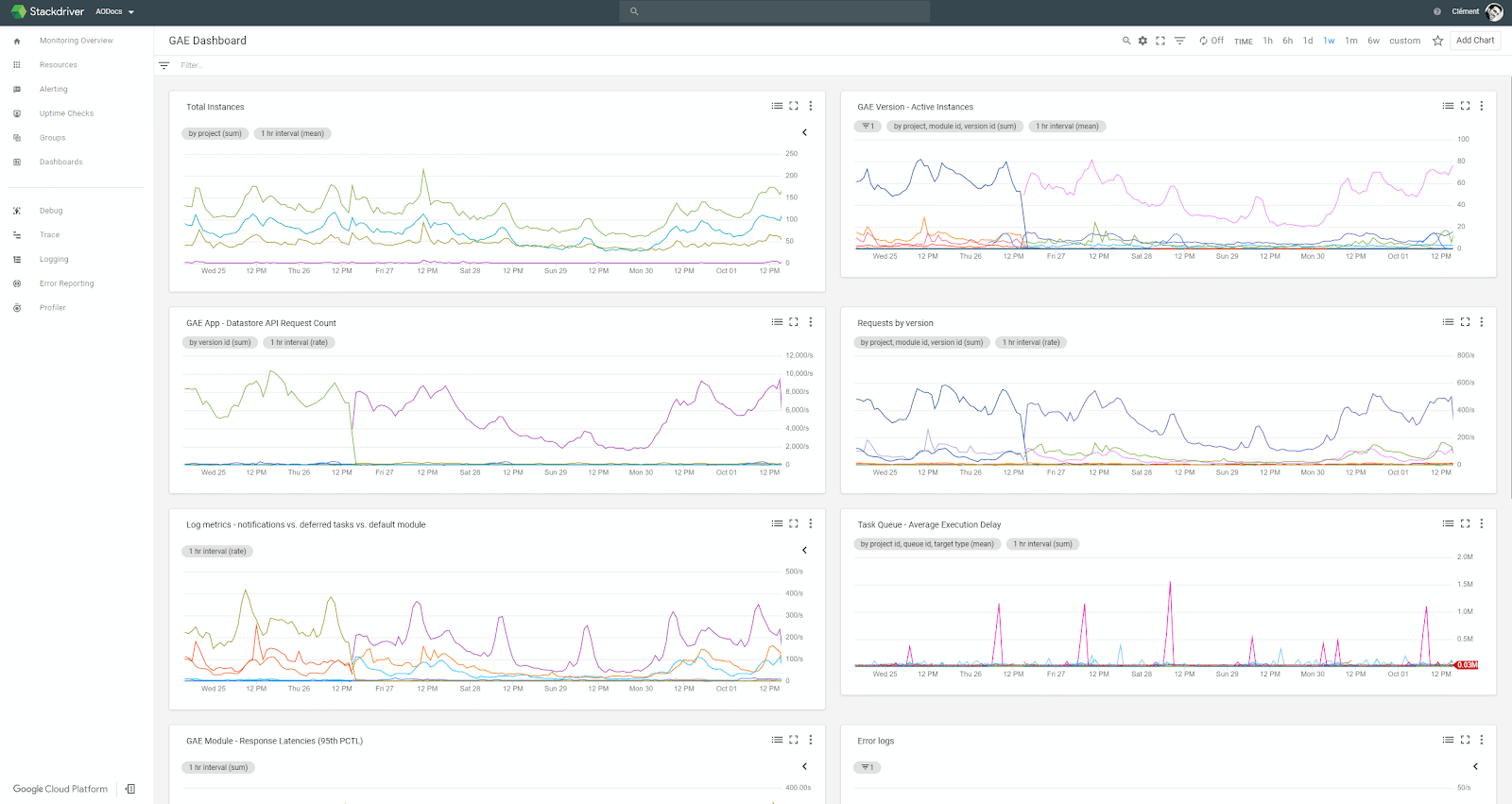
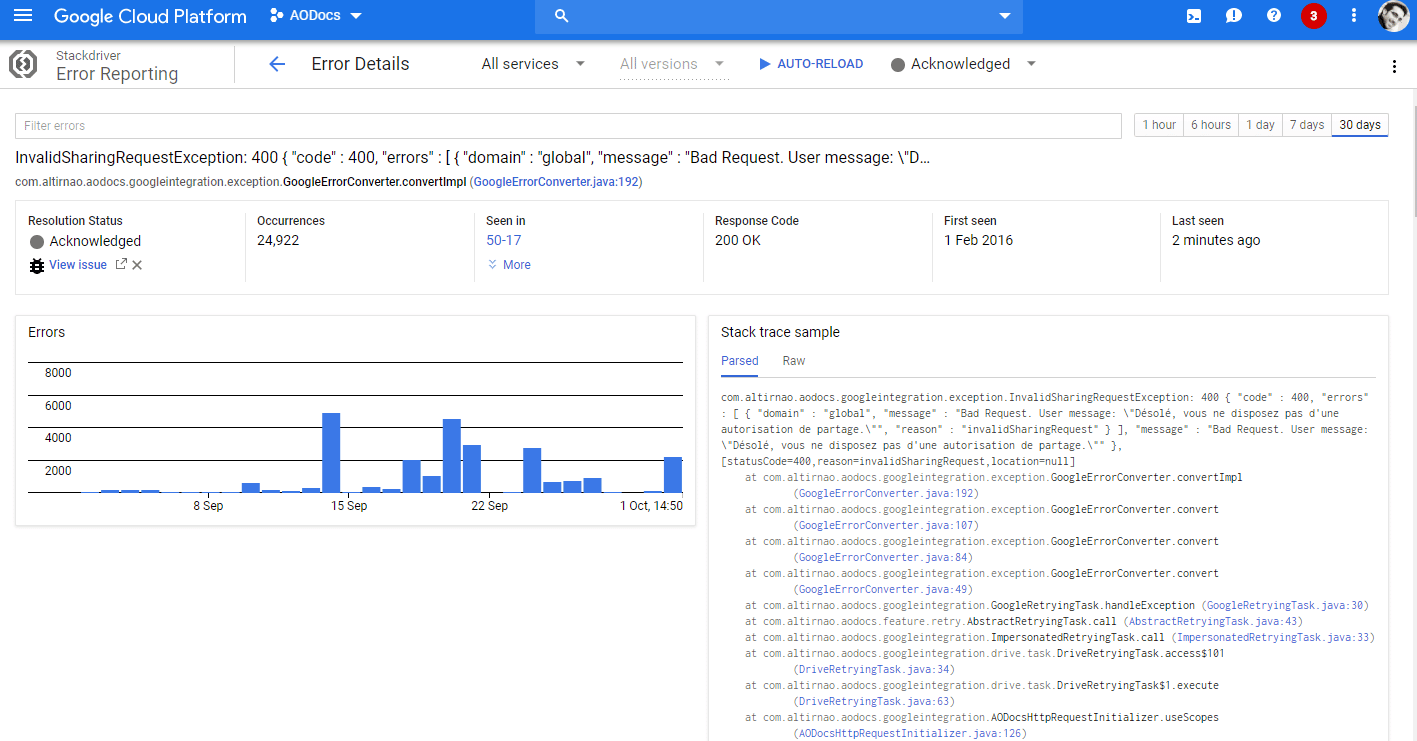
Logs et rapports d’erreur : Stackdriver assure
Le choix du framework de logs est ouvert
Que vous préfériez SLF4J, Commons Logging ou Lombok, tout aboutit sur java.util.logging. La collecte ne dépend pas des goûts de chacun.
Stockage et analyse des logs : cap sur BigQuery
Stackdriver ne conserve les logs que 30 jours, mais une exportation dans BigQuery permet d’aller plus loin : analyse au long cours, recherche de latence, ou investigation poussée des incidents passés.
Détection automatique d’anomalies
Les stacktraces sont triées et regroupées, ce qui a permis d’attraper des bugs particulièrement discrets.
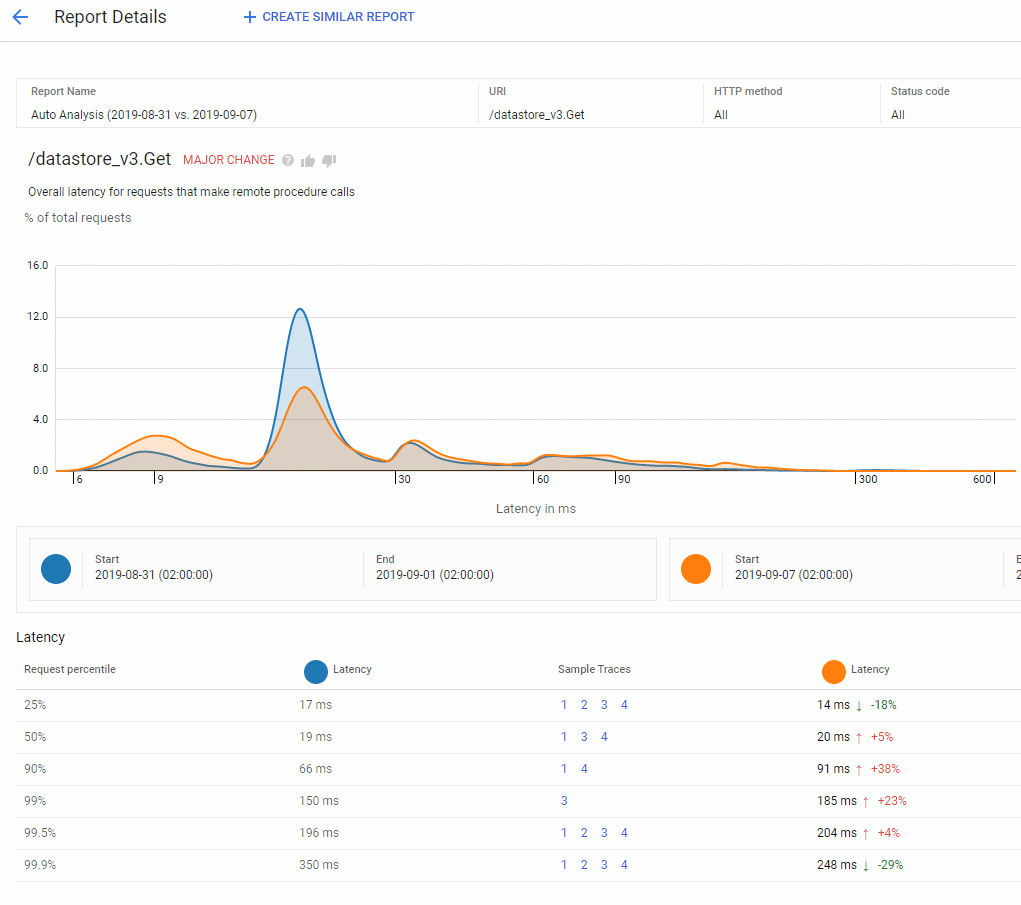
Stackdriver Trace : pour scruter la performance
Latence par chemin de requête
Repérer une anomalie ou un couac dans l’application devient immédiat.
Suivi automatisé pour App Engine
L’application bénéficie de métriques détaillées sans effort de développement supplémentaire.
Possibilité d’ajouter ses propres spans
L’écosystème s’appuie sur OpenCensus pour enrichir le diagnostic.
Comparer les distributions de latence entre versions
Les rapports, automatiques ou à la demande, affûtent l’analyse des performances d’une version à l’autre.

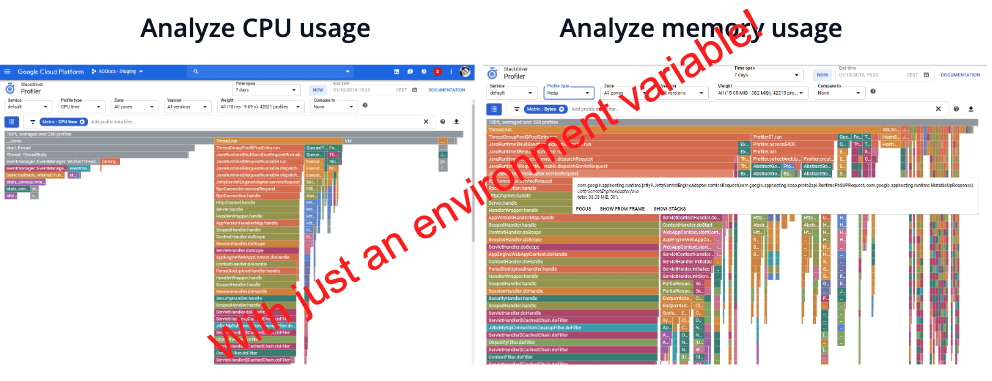
Stackdriver Profiler : creuser toujours plus loin
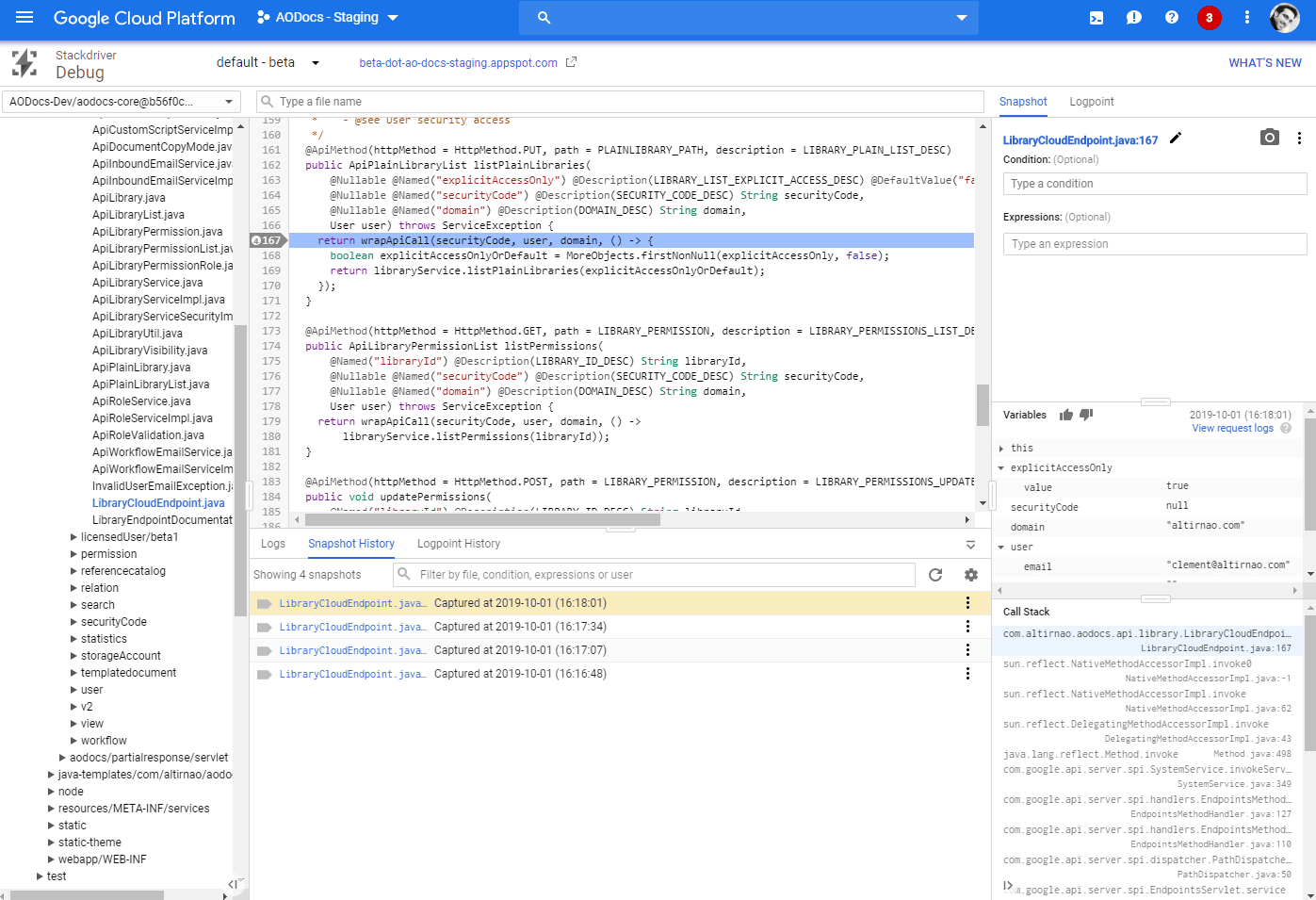
Déboguer avec Stackdriver
Placer un “point d’arrêt” en production
Directement depuis IntelliJ ou en ligne, sans impacter réellement les performances, tout en ayant accès aux variables d’exécution au bon moment.
Ajouter un log ponctuel précisément où il faut
Le système sait où et quand le faire, plus besoin d’hésiter avant d’ajouter un point de contrôle temporaire.
Une expérience agréable, même si l’usage reste ponctuel
Il faut l’avouer, cet outil impressionne mais sert surtout de corde de rappel lors de cas spécifiques.
Jean-Marc Leoni : le “serverless” vu depuis AWS, en combinant Spring et AWS Batch pour les traitements longs et asynchrones dans Java.
Serverless appliqué au traitement batch
Dans certains cas, la fonction-as-a-service (FaaS) s’avère utile pour :
- Traiter les données une à une pour l’enrichissement ou le nettoyage
- Piloter sans effort des volumes modestes
D’autres contextes exposent ses limites :
- Impossible quand toutes les données doivent tenir en mémoire
- Inadéquat si le traitement ne se distribue pas
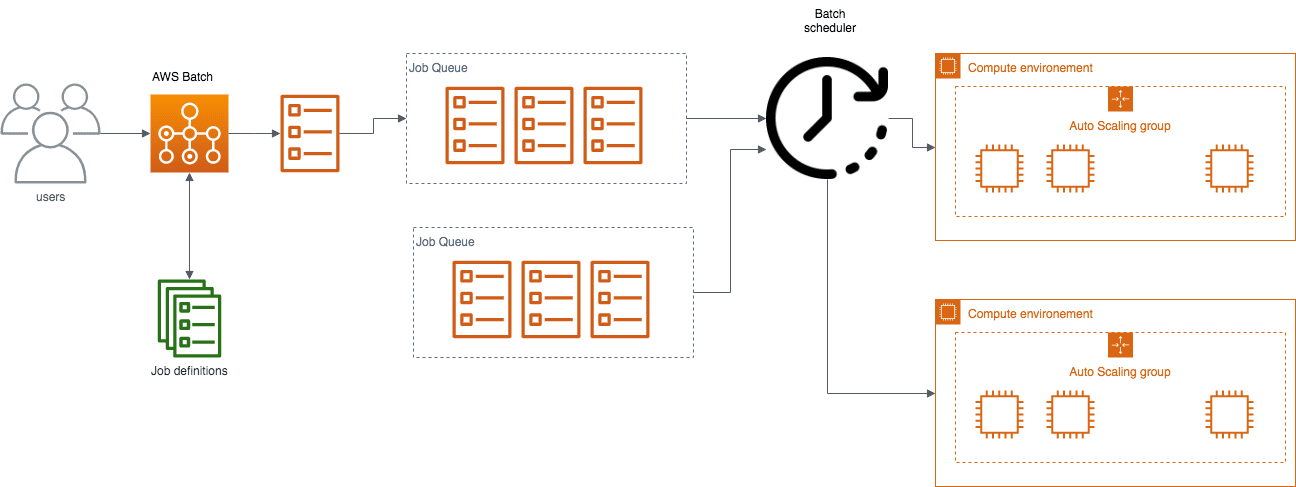
AWS Batch
AWS Batch orchestre les traitements massifs de longue haleine. Il s’appuie sur plusieurs piliers :
- Job Definition : image Docker, commandes associées, dimensionement CPU/mémoire
- Job : tâche concrète, lancée sur un Compute Environment
- Queue : file d’attente des traitements
- Compute Environment : réserve de machines provisionnées automatiquement, à la taille voulue
Et Spring dans tout ça ?
Spring Batch accélère la création de pipelines de traitement, rendant les étapes plus claires :
- Définition naturellement découpée des phases
- Connexion native avec JDBC/JPA
Spring Cloud, de son côté, simplifie l’intégration aux environnements cloud :
- Base de données managée
- Déploiement microservices facilité
Pour terminer, Jean-Marc Leoni a partagé un projet de référence sur Github lors du meetup. L’avancée du cloud continue de transformer la façon d’imaginer, développer et exécuter les traitements, jusqu’à rendre la technique presque invisible derrière chaque brique applicative, chaque calcul expédié vers le nuage.

